Sparkling Water
What is Sparkling Water?
Sparkling Water is an integration work done by Michal Malohlava that brings together the two open-source platform H2O and Spark. Because of this integration H2O and users can takes advantage of H2O's algorithms, Spark SQL, and both parsers. The typical use case is to load data either into H2O or Spark, use Spark SQL to make a query, feed the results into H2O Deep Learning to build a model, make their predictions, and then use the results again in Spark.
The current integration will require an installation of Spark. To launch a Spark App the user will be required to start up a Spark cluster with H2O instances sitting in the same JVM. The user will specify the number of woker nodes and amount of memory on each node when starting a Spark Shell or when submitting a job to YARN on Hadoop.
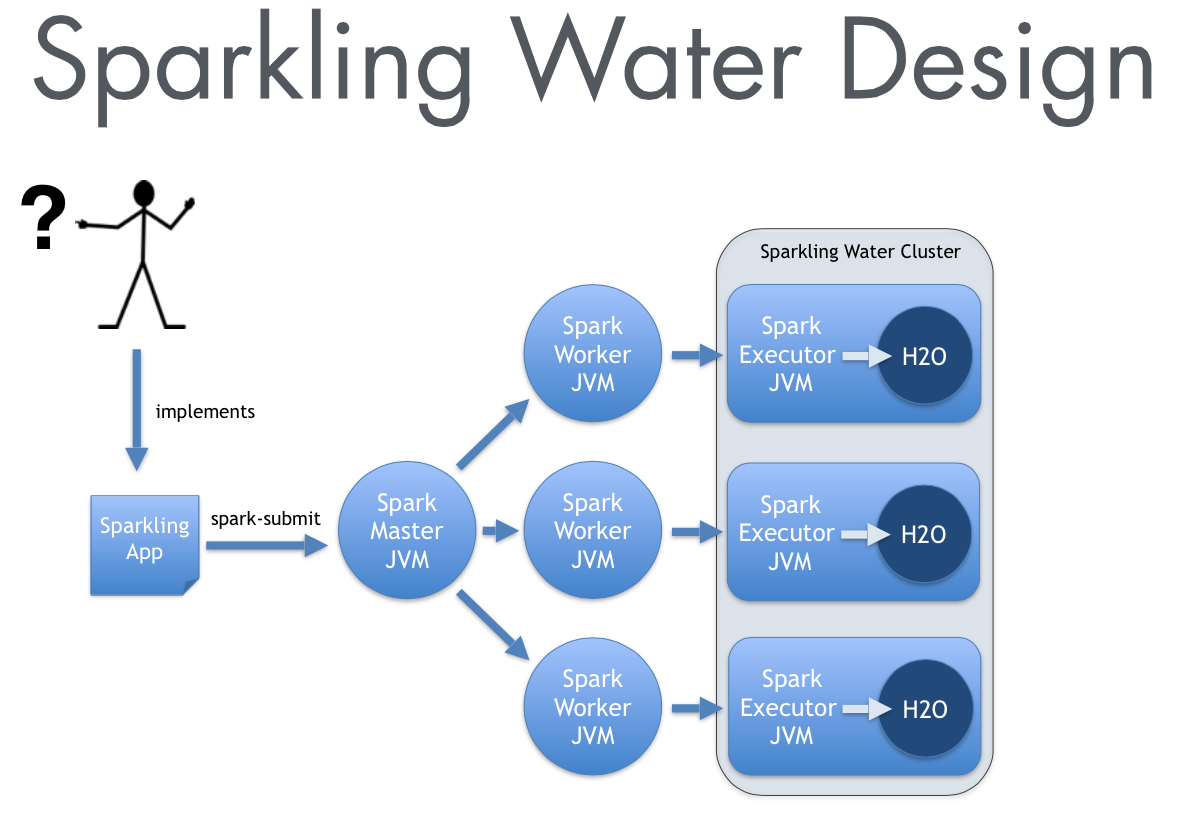
Data Distribution
The key to this tutorial is understanding how data is distributed on the Sparkling Water cluster. After data has been imported into either Spark or H2O we can publish H2O data frames as SchemaRDDs in Spark in order to run Spark SQL without replicating the data. However reading data into H2O from Spark will require a one time load of the data into H2O which isn't done as cheaply.

Setup and Installation
Prerequisites: Spark 1.2+
First install Spark and set the necessary environmental variables and then download the latest version of Sparkling Water to get started.
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.2.1-bin-hadoop2.4.tgz
tar -xvf spark-1.2.1-bin-hadoop2.4.tgz
cd spark-1.2.1-bin-hadoop2.4
export SPARK_HOME=`pwd`
wget http://h2o-release.s3.amazonaws.com/sparkling-water/master/95/sparkling-water-0.2.12-95.zip
unzip sparkling-water-0.2.12-95.zip
cd sparkling-water-0.2.12-95
To launch a Sparkling Shell which is essentially a Spark Shell with H2O classes launched with the shell from the command line run the script sparkling-shell.
bin/sparkling-shell
Launch H2O on the Spark Cluster
Now that we've started a Spark cluster we move on to launch H2O JVM atop each of the Spark executors and import H2O Context. Now the user can use all of the H2O classes that the Sparkling shell was launched with.
// Prepare application environment
import org.apache.spark.h2o._
import org.apache.spark.examples.h2o._
import water.Key
// Start H2O
val h2oContext = new H2OContext(sc).start()
import h2oContext._
Load data into the key-value store in the H2O cluster
This tutorial will be using a simple airlines dataset that comes with your installation of H2O. This airlines dataset is actually a subset of the 20+ years worth of flight data publicly available. We will be using the dataset to predict whether flights are Delayed during Departure. At this point you may type openFlow to access the new H2O webUI that will list all frames currently in the KV store.
// Import all year airlines into H2O
import java.io.File
val dataFile = "examples/smalldata/year2005.csv.gz"
val airlinesData = new DataFrame(new File(dataFile))
Load data Spark
At the same time load weather data into Spark instead of H2O, this is mainly to demonstrate how the transparent integration of H2O Data Frames allow the user to use H2ORDDs and SparkRDDs not only from the same API but within sql queries. The following weather dataset is for the airport Ohare in Chicago during the year 2005.
// Import weather data into Spark
val weatherDataFile = "examples/smalldata/Chicago_Ohare_International_Airport.csv"
val wrawdata = sc.textFile(weatherDataFile,8).cache()
val weatherTable = wrawdata.map(_.split(",")).map(row => WeatherParse(row)).filter(!_.isWrongRow())
Filter
Use Spark to filter out all flights coming from Ohare in the airlines dataset.
// Transfer data from H2O to Spark RDD
val airlinesTable : RDD[Airlines] = toRDD[Airlines](airlinesData)
val flightsToORD = airlinesTable.filter(f => f.Origin==Some("ORD"))
Spark SQL on the two data frames
Import SQL Context and publish the airlines dataset as a SchemaRDD which will allow us to join our flight and weather dataframes together. In the sql query we only ask for the columns relevant for the model build dumping columns with many NA values or cheating columns such as the column Cancelled. So in addition to the original feature set we've added on temperature and precipitation information for each flight.
// Use Spark SQL to join flight and weather data in spark
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
import sqlContext._
flightsToORD.registerTempTable("FlightsToORD")
weatherTable.registerTempTable("WeatherORD")
// Perform SQL Join on both tables
val bigTable = sql(
"""SELECT
|f.Year,f.Month,f.DayofMonth,
|f.UniqueCarrier,f.FlightNum,f.TailNum,
|f.Origin,f.Distance,
|w.TmaxF,w.TminF,w.TmeanF,w.PrcpIn,w.SnowIn,w.CDD,w.HDD,w.GDD,
|f.IsDepDelayed
|FROM FlightsToORD f
|JOIN WeatherORD w
|ON f.Year=w.Year AND f.Month=w.Month AND f.DayofMonth=w.Day""".stripMargin)
Set columns to factors
It is important to set integer columns to factors before running any models, otherwise Deep Learning will assume it is building a regression model rather than a binomial or multinomial model.
val trainFrame:DataFrame = bigTable
trainFrame.replace(19, trainFrame.vec("IsDepDelayed").toEnum)
trainFrame.update(null)
Create our predictive models
Now that we have our training frame in H2O we can build a GLM and Deep Learning Model. To create a Deep Learning model, import the necessary classes and set all the parameters for the model in the script. Then after launching and completing the job, grab the predictions frame from H2O and move it back into Spark as a SchemaRDD.
// Run deep learning to produce model estimating arrival delay
import hex.deeplearning.DeepLearning
import hex.deeplearning.DeepLearningModel.DeepLearningParameters
val dlParams = new DeepLearningParameters()
dlParams._epochs = 100
dlParams._train = trainFrame
dlParams._response_column = 'IsDepDelayed
dlParams._variable_importances = true
dlParams._destination_key = Key.make("dlModel.hex").asInstanceOf[water.Key[Frame]]
// Create a job
val dl = new DeepLearning(dlParams)
val dlModel = dl.trainModel.get
// Use model to estimate delay on training data
val predictionH2OFrame = dlModel.score(bigTable)('predict)
val predictionsFromModel = toRDD[DoubleHolder](predictionH2OFrame).collect.map(_.result.getOrElse(Double.NaN))
Do the same with GLM.
// Run GLM to produce model estimating arrival delay
import hex.glm.GLMModel.GLMParameters.Family
import hex.glm.GLM
import hex.glm.GLMModel.GLMParameters
val glmParams = new GLMParameters(Family.binomial)
glmParams._train = bigTable
glmParams._response_column = 'IsDepDelayed
glmParams._alpha = Array[Double](0.5)
glmParams._destination_key = Key.make("glmModel.hex").asInstanceOf[water.Key[Frame]]
val glm = new GLM(glmParams)
val glmModel = glm.trainModel().get()
// Use model to estimate delay on training data
val predGLMH2OFrame = glmModel.score(bigTable)('predict)
val predGLMFromModel = toRDD[DoubleHolder](predictionH2OFrame).collect.map(_.result.getOrElse(Double.NaN))
// Grab the AUC value of each model
val glm_auc = glmModel.validation().auc()
val trainMetrics = binomialMM(dlModel, trainFrame)
val dl_auc = trainMetrics.auc.AUC
println("AUC of General Linear Model" + glm_auc)
println("AUC of Deep Learning Model" + dl_auc)