Real-time Predictions With H2O on Storm
This tutorial shows how to create a Storm topology can be used to make real-time predictions with H2O.
Where to find the latest version of this tutorial
1. What this tutorial covers
In this tutorial, we explore a combined modeling and streaming workflow as seen in the picture below:
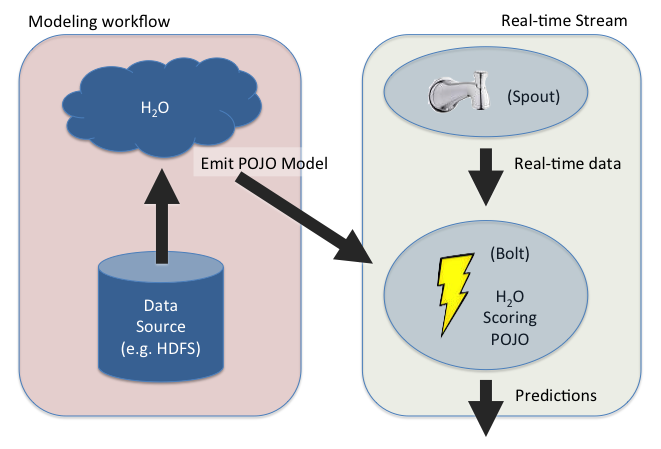
We produce a GBM model by running H2O and emitting a Java POJO used for scoring. The POJO is very lightweight and does not depend on any other libraries, not even H2O. As such, the POJO is perfect for embedding into third-party environments, like a Storm bolt.
This tutorial walks you through the following sequence:
- Installing the required software
- A brief discussion of the data
- Using R to build a gbm model in H2O
- Exporting the gbm model as a Java POJO
- Copying the generated POJO files into a Storm bolt build environment
- Building Storm and the bolt for the model
- Running a Storm topology with your model deployed
- Watching predictions in real-time
(Note that R is not strictly required, but is used for convenience by this tutorial.)
2. Installing the required software
2.1. Clone the required repositories from Github
$ git clone https://github.com/apache/storm.git
$ git clone https://github.com/0xdata/h2o-training.git
- NOTE: Building storm (c.f. Section 5) requires Maven. You can install Maven (version 3.x) by following the Maven installation instructions.
Navigate to the directory for this tutorial inside the h2o-training repository:
$ cd h2o-training/tutorials/streaming/storm
You should see the following files in this directory:
- README.md (This document)
- example.R (The R script that builds the GBM model and exports it as a Java POJO)
- training_data.csv (The data used to build the GBM model)
- live_data.csv (The data that predictions are made on; used to feed the spout in the Storm topology)
- H2OStormStarter.java (The Storm topology with two bolts: a prediction bolt and a classifying bolt)
- TestH2ODataSpout.java (The Storm spout which reads data from the live_data.csv file and passes each observation to the prediction bolt one observation at a time; this simulates the arrival of data in real-time)
And the following directories:
- premade_generated_model (For those people who have trouble building the model but want to try running with Storm anyway; you can ignore this directory if you successfully build your own generated_model later in the tutorial)
- images (Images for the tutorial documentation, you can ignore these)
- web (Contains the html and image files for watching the real-time prediction output (c.f. Section 8))
2.2. Install R
Get the latest version of R from CRAN and install it on your computer.
2.3. Install the H2O package for R
Note: The H2O package for R includes both the R code as well as the main H2O jar file. This is all you need to run H2O locally on your laptop.
Step 1: Start R
$ R
Step 2: Install H2O from CRAN
> install.packages("h2o")
Note: For convenience, this tutorial was created with the Markov stable release of H2O (2.8.1.1) from CRAN, as shown above. Later versions of H2O will also work.
2.4. Development environment
This tutorial was developed with the following software environment. (Other environments will work, but this is what we used to develop and test this tutorial.)
- H2O 2.8.1.1 (Markov)
- MacOS X (Mavericks)
- java version "1.7.0_51" (JDK)
- R 3.1.2
- Storm git hash (insert here)
- curl 7.30.0 (x86_64-apple-darwin13.0) libcurl/7.30.0 SecureTransport zlib/1.2.5
- Maven (Apache Maven 3.0.4)
For viewing predictions in real-time (Section 8) you will need the following:
- npm (1.3.11) (
$ brew install npm) - http-server (
$ npm install http-server -g) - A modern web browser (animations depend on D3)
3. A brief discussion of the data
Let's take a look at a small piece of the training_data.csv file for a moment. This is a synthetic data set created for this tutorial.
$ head -n 20 training_data.csv
| Label | Has4Legs | CoatColor | HairLength | TailLength | EnjoysPlay | StaresOutWindow | HoursSpentNapping | RespondsToCommands | EasilyFrightened | Age | Noise1 | Noise2 | Noise3 | Noise4 | Noise5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dog | 1 | Brown | 0 | 2 | 1 | 1 | 2 | 1 | 0 | 4 | 0.852352328598499 | 0.229839221341535 | 0.576096264412627 | 0.0105558061040938 | 0.470826978096738 |
| dog | 1 | Brown | 1 | 1 | 1 | 1 | 5 | 0 | 0 | 16 | 0.928460991941392 | 0.98618565662764 | 0.553872474469244 | 0.932764369761571 | 0.435074317501858 |
| dog | 1 | Grey | 1 | 10 | 1 | 1 | 2 | 1 | 0 | 5 | 0.658247262472287 | 0.379703616956249 | 0.767817151267081 | 0.840509128058329 | 0.538852979661897 |
| dog | 1 | Grey | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 2 | 0.210346511797979 | 0.912498287158087 | 0.757371880114079 | 0.915149037493393 | 0.27393517526798 |
| dog | 1 | Brown | 1 | 5 | 1 | 0 | 10 | 1 | 0 | 20 | 0.770219849422574 | 0.999768516747281 | 0.482816896401346 | 0.904691722244024 | 0.232283475110307 |
| cat | 1 | Grey | 1 | 6 | 1 | 1 | 3 | 0 | 1 | 10 | 0.499049366684631 | 0.690937616396695 | 0.00580681697465479 | 0.516113663092256 | 0.161103375256062 |
| dog | 1 | Spotted | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 17 | 0.980622073402628 | 0.193929805886 | 0.50500241224654 | 0.848579460754991 | 0.750856031663716 |
| cat | 1 | Spotted | 1 | 7 | 0 | 1 | 5 | 0 | 1 | 9 | 0.298585452139378 | 0.425832540960982 | 0.816698056645691 | 0.0246927759144455 | 0.692579888971522 |
| dog | 1 | Grey | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 3 | 0.724013194208965 | 0.120883409865201 | 0.754467910155654 | 0.43663241318427 | 0.0592612794134766 |
| cat | 1 | Black | 0 | 7 | 0 | 1 | 5 | 0 | 1 | 5 | 0.849093642551452 | 0.0961945767048746 | 0.588080670218915 | 0.0478771082125604 | 0.211781785823405 |
| dog | 1 | Grey | 1 | 1 | 1 | 0 | 2 | 0 | 1 | 1 | 0.362678906414658 | 0.54775956296362 | 0.522148486692458 | 0.903857592027634 | 0.496479033492506 |
| dog | 1 | Spotted | 0 | 1 | 1 | 1 | 2 | 1 | 0 | 3 | 0.745238043367863 | 0.0181446429342031 | 0.33444849960506 | 0.550831729080528 | 0.625747208483517 |
| dog | 1 | Spotted | 1 | 4 | 1 | 1 | 2 | 1 | 0 | 20 | 0.693285189568996 | 0.69526576064527 | 0.386858200887218 | 0.235119538847357 | 0.401590927504003 |
| cat | 1 | Spotted | 1 | 8 | 1 | 1 | 3 | 0 | 0 | 3 | 0.695167713565752 | 0.81692309374921 | 0.530564708868042 | 0.081766308285296 | 0.277844901895151 |
| cat | 1 | White | 1 | 8 | 0 | 1 | 5 | 0 | 0 | 3 | 0.0237249641213566 | 0.867370987776667 | 0.855278167175129 | 0.284646768355742 | 0.566314383875579 |
| cat | 1 | Black | 1 | 5 | 1 | 1 | 2 | 0 | 1 | 16 | 0.281967194052413 | 0.798100406536832 | 0.306403951486573 | 0.681048742029816 | 0.237810888560489 |
| cat | 1 | Grey | 1 | 7 | 1 | 1 | 3 | 1 | 1 | 16 | 0.178538456792012 | 0.566589535912499 | 0.297640548087656 | 0.634627313353121 | 0.677242929581553 |
| cat | 1 | Spotted | 1 | 8 | 0 | 0 | 10 | 0 | 1 | 3 | 0.219212393043563 | 0.482533045113087 | 0.739678716054186 | 0.132942436495796 | 0.100684949662536 |
Note that the first row in the training data set is a header row specifying the column names.
The response column (i.e. the "y" column) we want to make predictions for is Label. It's a binary column, so we want to build a classification model. The response column is categorical, and contains two levels, 'cat' and 'dog'. Note that the ratio of dogs to cats is 3:1.
The remaining columns are all input features (i.e. the "x" columns) we use to predict whether each new observation is a 'cat' or a 'dog'. The input features are a mix of integer, real, and categorical columns.
4. Using R to build a gbm model in H2O and export it as a Java POJO
4.1. Build and export the model
The example.R script builds the model and exports the Java POJO to the generated_model temporary directory. Run example.R as follows:
$ R -f example.R
R version 3.1.2 (2014-10-31) -- "Pumpkin Helmet"
Copyright (C) 2014 The R Foundation for Statistical Computing
Platform: x86_64-apple-darwin13.4.0 (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> #
> # Example R code for generating an H2O Scoring POJO.
> #
>
> # "Safe" system. Error checks process exit status code. stop() if it failed.
> safeSystem <- function(x) {
+ print(sprintf("+ CMD: %s", x))
+ res <- system(x)
+ print(res)
+ if (res != 0) {
+ msg <- sprintf("SYSTEM COMMAND FAILED (exit status %d)", res)
+ stop(msg)
+ }
+ }
>
> library(h2o)
Loading required package: RCurl
Loading required package: bitops
Loading required package: rjson
Loading required package: statmod
Loading required package: survival
Loading required package: splines
Loading required package: tools
----------------------------------------------------------------------
Your next step is to start H2O and get a connection object (named
'localH2O', for example):
> localH2O = h2o.init()
For H2O package documentation, ask for help:
> ??h2o
After starting H2O, you can use the Web UI at http://localhost:54321
For more information visit http://docs.h2o.ai
----------------------------------------------------------------------
Attaching package: ‘h2o’
The following objects are masked from ‘package:base’:
ifelse, max, min, strsplit, sum, tolower, toupper
>
> cat("Starting H2O\n")
Starting H2O
> myIP <- "localhost"
> myPort <- 54321
> h <- h2o.init(ip = myIP, port = myPort, startH2O = TRUE)
H2O is not running yet, starting it now...
Note: In case of errors look at the following log files:
/var/folders/tt/g5d7cr8d3fg84jmb5jr9dlrc0000gn/T//Rtmps9bRj4/h2o_tomk_started_from_r.out
/var/folders/tt/g5d7cr8d3fg84jmb5jr9dlrc0000gn/T//Rtmps9bRj4/h2o_tomk_started_from_r.err
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)
Successfully connected to http://localhost:54321
R is connected to H2O cluster:
H2O cluster uptime: 1 seconds 587 milliseconds
H2O cluster version: 2.8.1.1
H2O cluster name: H2O_started_from_R
H2O cluster total nodes: 1
H2O cluster total memory: 3.56 GB
H2O cluster total cores: 8
H2O cluster allowed cores: 2
H2O cluster healthy: TRUE
Note: As started, H2O is limited to the CRAN default of 2 CPUs.
Shut down and restart H2O as shown below to use all your CPUs.
> h2o.shutdown(localH2O)
> localH2O = h2o.init(nthreads = -1)
>
> cat("Building GBM model\n")
Building GBM model
> df <- h2o.importFile(h, "training_data.csv");
^M | ^M | | 0%^M | ^M |======================================================================| 100%
> y <- "Label"
> x <- c("NumberOfLegs","CoatColor","HairLength","TailLength","EnjoysPlay","StairsOutWindow","HoursSpentNapping","RespondsToCommands","EasilyFrightened","Age", "Noise1", "Noise2", "Noise3", "Noise4", "Noise5")
> gbm.h2o.fit <- h2o.gbm(data = df, y = y, x = x, n.trees = 10)
^M | ^M | | 0%^M | ^M |======================================================================| 100%
>
> cat("Downloading Java prediction model code from H2O\n")
Downloading Java prediction model code from H2O
> model_key <- gbm.h2o.fit@key
> tmpdir_name <- "generated_model"
> cmd <- sprintf("rm -fr %s", tmpdir_name)
> safeSystem(cmd)
[1] "+ CMD: rm -fr generated_model"
[1] 0
> cmd <- sprintf("mkdir %s", tmpdir_name)
> safeSystem(cmd)
[1] "+ CMD: mkdir generated_model"
[1] 0
> cmd <- sprintf("curl -o %s/GBMPojo.java http://%s:%d/2/GBMModelView.java?_modelKey=%s", tmpdir_name, myIP, myPort, model_key)
> safeSystem(cmd)
[1] "+ CMD: curl -o generated_model/GBMPojo.java http://localhost:54321/2/GBMModelView.java?_modelKey=GBM_9d538f637ef85c78d6e2fea88ad54bc9"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
^M 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0^M100 27041 0 27041 0 0 2253k 0 --:--:-- --:--:-- --:--:-- 2400k
[1] 0
> cmd <- sprintf("curl -o %s/h2o-model.jar http://127.0.0.1:54321/h2o-model.jar", tmpdir_name)
> safeSystem(cmd)
[1] "+ CMD: curl -o generated_model/h2o-model.jar http://127.0.0.1:54321/h2o-model.jar"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
^M 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0^M100 8085 100 8085 0 0 3206k 0 --:--:-- --:--:-- --:--:-- 3947k
[1] 0
> cmd <- sprintf("sed -i '' 's/class %s/class GBMPojo/' %s/GBMPojo.java", model_key, tmpdir_name)
> safeSystem(cmd)
[1] "+ CMD: sed -i '' 's/class GBM_9d538f637ef85c78d6e2fea88ad54bc9/class GBMPojo/' generated_model/GBMPojo.java"
[1] 0
>
> cat("Note: H2O will shut down automatically if it was started by this R script and the script exits\n")
Note: H2O will shut down automatically if it was started by this R script and the script exits
>
4.2. Look at the output
The generated_model directory is created and now contains two files:
$ ls -l generated_model
mbp2:storm tomk$ ls -l generated_model/
total 72
-rw-r--r-- 1 tomk staff 27024 Nov 15 16:49 GBMPojo.java
-rw-r--r-- 1 tomk staff 8085 Nov 15 16:49 h2o-model.jar
The h2o-model.jar file contains the interface definition, and the GBMPojo.java file contains the Java code for the POJO model.
The following three sections from the generated model are of special importance.
4.2.1. Class name
public class GBMPojo extends water.genmodel.GeneratedModel {
This is the class to instantiate in the Storm bolt to make predictions. (Note that we simplified the class name using sed as part of the R script that exported the model. By default, the class name has a long UUID-style name.)
4.2.2. Predict method
public final float[] predict( double[] data, float[] preds)
predict() is the method to call to make a single prediction for a new observation. data is the input, and preds is the output. The return value is just preds, and can be ignored.
Inputs and Outputs must be numerical. Categorical columns must be translated into numerical values using the DOMAINS mapping on the way in. Even if the response is categorical, the result will be numerical. It can be mapped back to a level string using DOMAINS, if desired. When the response is categorical, the preds response is structured as follows:
preds[0] contains the predicted level number
preds[1] contains the probability that the observation is level0
preds[2] contains the probability that the observation is level1
...
preds[N] contains the probability that the observation is levelN-1
sum(preds[1] ... preds[N]) == 1.0
In this specific case, that means:
preds[0] contains 0 or 1
preds[1] contains the probability that the observation is ColInfo_15.VALUES[0]
preds[2] contains the probability that the observation is ColInfo_15.VALUES[1]
4.2.3. DOMAINS array
// Column domains. The last array contains domain of response column.
public static final String[][] DOMAINS = new String[][] {
/* NumberOfLegs */ ColInfo_0.VALUES,
/* CoatColor */ ColInfo_1.VALUES,
/* HairLength */ ColInfo_2.VALUES,
/* TailLength */ ColInfo_3.VALUES,
/* EnjoysPlay */ ColInfo_4.VALUES,
/* StairsOutWindow */ ColInfo_5.VALUES,
/* HoursSpentNapping */ ColInfo_6.VALUES,
/* RespondsToCommands */ ColInfo_7.VALUES,
/* EasilyFrightened */ ColInfo_8.VALUES,
/* Age */ ColInfo_9.VALUES,
/* Noise1 */ ColInfo_10.VALUES,
/* Noise2 */ ColInfo_11.VALUES,
/* Noise3 */ ColInfo_12.VALUES,
/* Noise4 */ ColInfo_13.VALUES,
/* Noise5 */ ColInfo_14.VALUES,
/* Label */ ColInfo_15.VALUES
};
The DOMAINS array contains information about the level names of categorical columns. Note that Label (the column we are predicting) is the last entry in the DOMAINS array.
5. Building Storm and the bolt for the model
5.1 Build storm and import into IntelliJ
To build storm navigate to the cloned repo and install via Maven:
$ cd storm && mvn clean install -DskipTests=true
Once storm is built, open up your favorite IDE to start building the h2o streaming topology. In this tutorial, we will be using IntelliJ.
To import the storm-starter project into your IntelliJ please follow these screenshots:
Click on "Import Project" and find the storm repo. Select storm and click "OK"
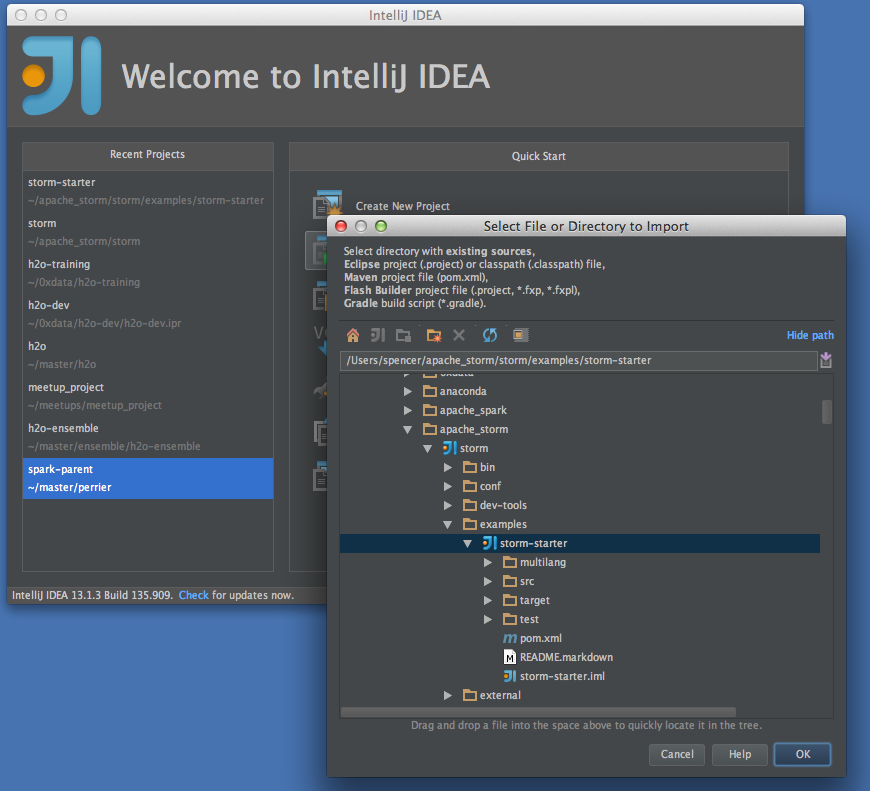
Import the project from extrenal model using Maven, click "Next"
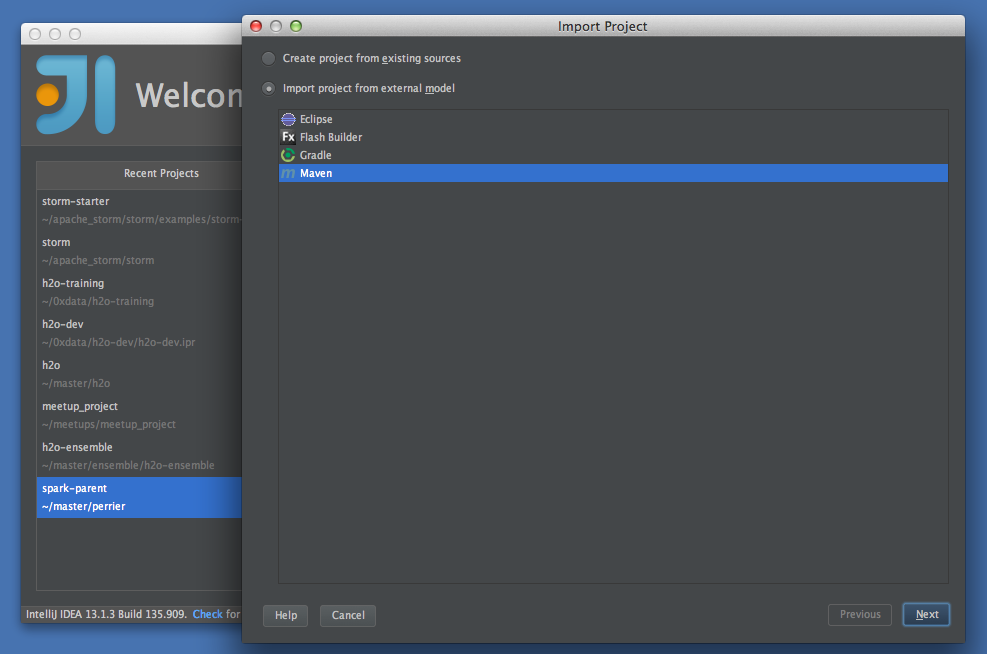
Ensure that "Import Maven projects automatically" check box is clicked (it's off by default), click "Next"
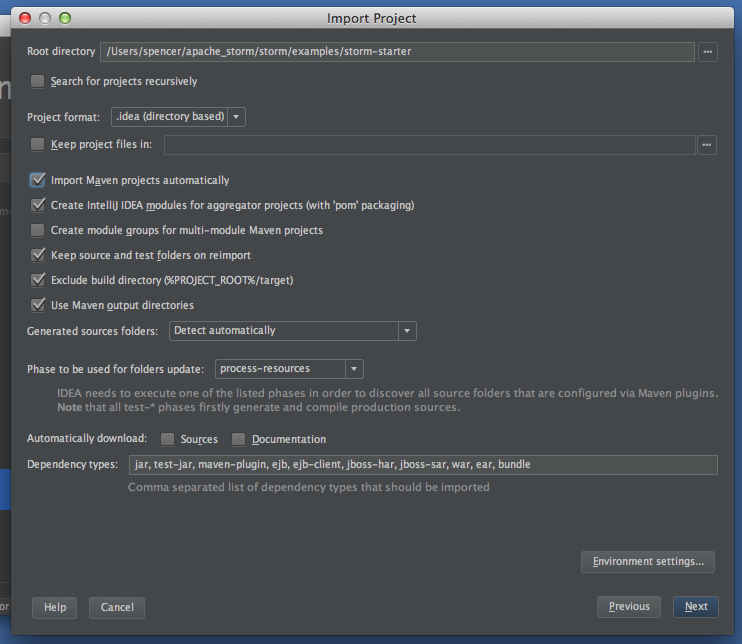
That's it! Now click through the remaining prompts (Next -> Next -> Next -> Finish).
Once inside the project, open up storm-starter/test/jvm/storm.starter. Yes, we'll be working out of the test directory.
5.2 Build the topology
The topology we've prepared has one spout TestH2ODataSpout and two bolts (a "Predict Bolt" and a "Classifier Bolt"). Please copy the pre-built bolts and spout into the test directory in IntelliJ.
$ cp H2OStormStarter.java /PATH_TO_STORM/storm/examples/storm-starter/test/jvm/storm/starter/
$ cp TestH2ODataSpout.java /PATH_TO_STORM/storm/examples/storm-starter/test/jvm/storm/starter/
Your project should now look like this:
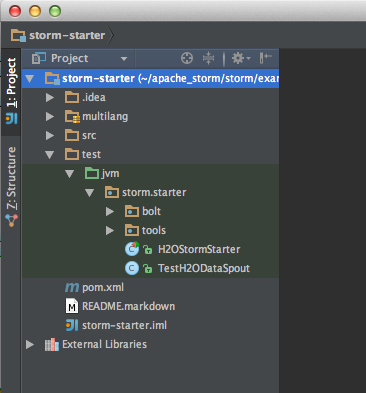
6. Copying the generated POJO files into a Storm bolt build environment
We are now ready to import the H2O pieces into the IntelliJ project. We'll need to add the h2o-model.jar and the scoring POJO.
To import the h2o-model.jar into your IntelliJ project, please follow these screenshots:
File > Project Structure…

Click the "+" to add a new dependency
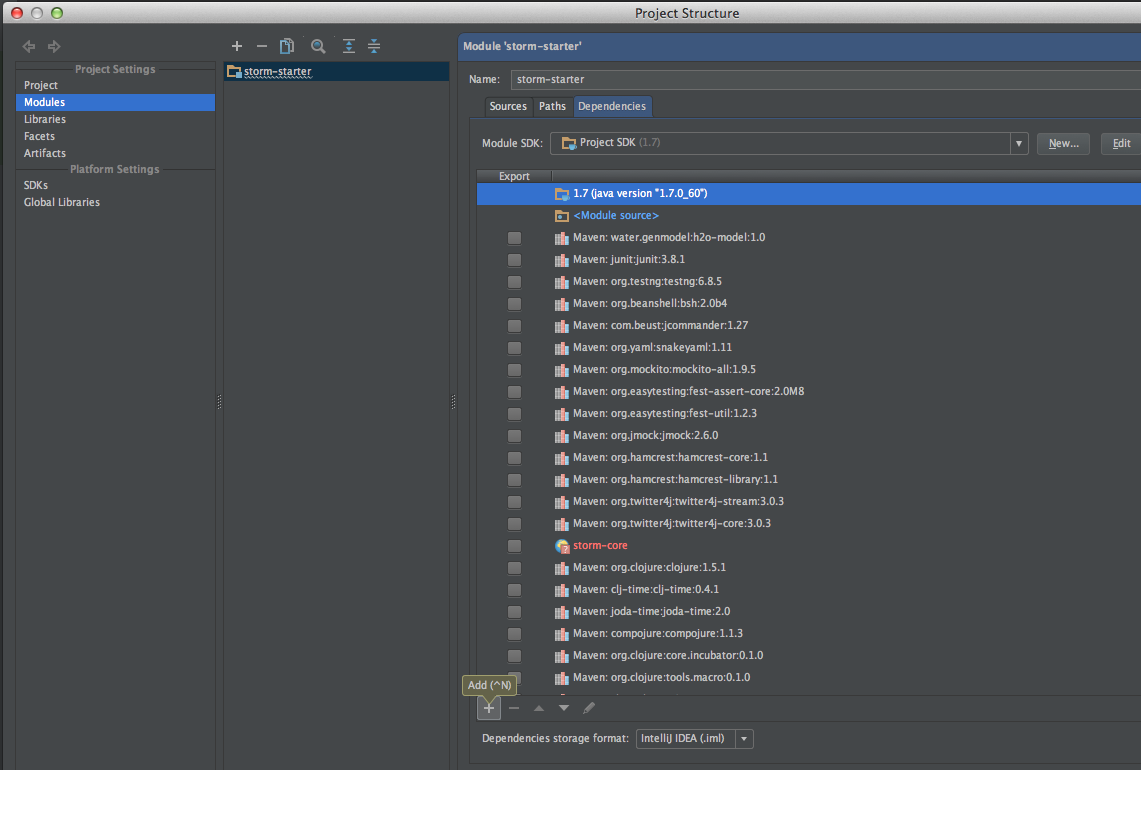
Click on Jars or directories…
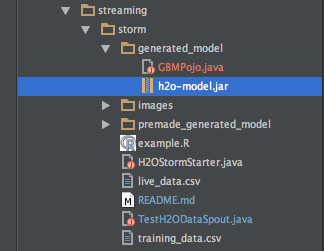
Find the h2o-model.jar that we previously downloaded with the R script in section 4
Click "OK", then "Apply", then "OK".
You now have the h2o-model.jar as a depencny in your project.
We now copy over the POJO from section 4 into our storm project.
$ cp ./generated_model/GBMPojo.java /PATH_TO_STORM/storm/examples/storm-starter/test/jvm/storm/starter/
OR if you were not able to build the GBMPojo, copy over the pre-generated version:
$ cp ./premade_generated_model/GBMPojo.java /PATH_TO_STORM/storm/examples/storm-starter/test/jvm/storm/starter/
Your storm-starter project directory should now look like this:
In order to use the GBMPojo class, our PredictionBolt in H2OStormStarter has the following "execute" block:
@Override public void execute(Tuple tuple) {
GBMPojo p = new GBMPojo();
// get the input tuple as a String[]
ArrayList<String> vals_string = new ArrayList<String>();
for (Object v : tuple.getValues()) vals_string.add((String)v);
String[] raw_data = vals_string.toArray(new String[vals_string.size()]);
// the score pojo requires a single double[] of input.
// We handle all of the categorical mapping ourselves
double data[] = new double[raw_data.length-1]; //drop the Label
String[] colnames = tuple.getFields().toList().toArray(new String[tuple.size()]);
// if the column is a factor column, then look up the value, otherwise put the double
for (int i = 1; i < raw_data.length; ++i) {
data[i-1] = p.getDomainValues(colnames[i]) == null
? Double.valueOf(raw_data[i])
: p.mapEnum(p.getColIdx(colnames[i]), raw_data[i]);
}
// get the predictions
float[] preds = new float[GBMPojo.NCLASSES+1];
p.predict(data, preds);
// emit the results
_collector.emit(tuple, new Values(raw_data[0], preds[1]));
_collector.ack(tuple);
}
The probability emitted is the probability of being a 'dog'. We use this probability to decide wether the observation is of type 'cat' or 'dog' depending on some threshold. This threshold was chosen such that the F1 score was maximized for the testing data (please see AUC and/or h2o.preformance() from R).
The ClassifierBolt then looks like:
public static class ClassifierBolt extends BaseRichBolt {
OutputCollector _collector;
final double _thresh = 0.54;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
String expected=tuple.getString(0);
double dogProb = tuple.getFloat(1);
String content = expected + "," + (dogProb <= _thresh ? "dog" : "cat");
try {
File file = new File("/Users/spencer/0xdata/h2o-training/tutorials/streaming/storm/web/out"); // EDIT ME! PUT YOUR PATH TO /web HERE
if (!file.exists()) file.createNewFile();
FileWriter fw = new FileWriter(file.getAbsoluteFile());
BufferedWriter bw = new BufferedWriter(fw);
bw.write(content);
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
_collector.emit(tuple, new Values(expected, dogProb <= _thresh ? "dog" : "cat"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("expected_class", "class"));
}
}
7. Running a Storm topology with your model deployed
Finally, we can run the topology by right-clicking on H2OStormStarter and running. Here's a screen shot of what that looks like:
8. Watching predictions in real-time

To watch the predictions in real time, we start up an http-server on port 4040 and navigate to http://localhost:4040.
In order to get http-server, install npm (you may need sudo):
$ brew install npm
$ npm install http-server -g
Once these are installed, you may navigate to the web directory and start the server:
$ cd web
$ http-server -p 4040 -c-1
Now open up your browser and navigate to http://localhost:4040. Requires a modern browser (depends on D3 for animation).
Here's a short video showing what it looks like all together.
Enjoy!
References
- CRAN
GBM
The Elements of Statistical Learning. Vol.1. N.p., page 339 Hastie, Trevor, Robert Tibshirani, and J Jerome H Friedman. Springer New York, 2001.
- H2O Markov stable release
- Java POJO
- R
- Storm